一次深入骨髓的 volatile 研究
 次阅读
次阅读
文章目录
作者:createchance
邮箱:createchance@163.com
日期:2020.05.30
版本:v1.0

本作品采用知识共享署名-相同方式共享 4.0 国际许可协议进行许可。
之前的文章 Java 并发基石篇 给大家详细分析了 java synchronize 的语义和具体的底层实现,在文章的末尾简单的分析了一下 volatile 的实现,但是并没有深入说明,这篇文章算是补充一下。
本文涉及的所有代码在这里:https://github.com/CreateChance/VolatileLearn
Java volatile 是如何实现的?
这一章节我们来讨论 java volatile 是如何实现的,整体上我们分为三个层面来讨论:
- Java 语言层面中 volatile 的语义
- Java 字节码/虚拟机层面的实现
- 具体硬件平台的实现
语言层面的实现
首先,我们需要知道 volatile 的在语言层面的语义是什么,要想知道这个内容,我们只要打开 java 语言规范即可知道(来自 Java 语言规范 8):
The Java programming language allows threads to access shared variables (§17.1). As a rule, to ensure that shared variables are consistently and reliably updated, a thread should ensure that it has exclusive use of such variables by obtaining a lock that, conventionally, enforces mutual exclusion for those shared variables.
The Java programming language provides a second mechanism, volatile fields, that is more convenient than locking for some purposes.
A field may be declared volatile, in which case the Java Memory Model ensures that all threads see a consistent value for the variable
从这段描述中我们可以知道 volatile 的语义了,它可以修饰 Java 对象中的字段,一旦某个字段被 volatile 修饰了,那么 Java 虚拟机会保证它在多个线程之间的可见性,也就是说,一个线程修改了这个字段,那么其他线程会立即看到这个修改。
但是我们看到,在 Java 语言规范中并没有说 volatile 的「有序性」,只是说了多线程的「可见性」。
字节码/虚拟机层面的实现
我们知道,volatile 只能用来修饰字段,所以我们研究的范围可以缩小为字段。当我们使用 volatile 修饰一个类的字段时,得到的字节码是什么样的呢?
以下面的代码为例:
/**
* 学习字节码层面的 volatile 实现
*
* @author createchance
* @since 2020/5/24
*/
public class HelloVolatile {
private volatile int volatileValue;
private int nonVolatileValue;
}
我们查看如上 volatile 字段字节码信息:
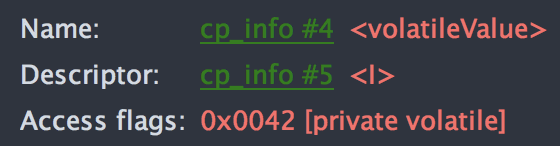
非 volatile 字段的字节码信息:
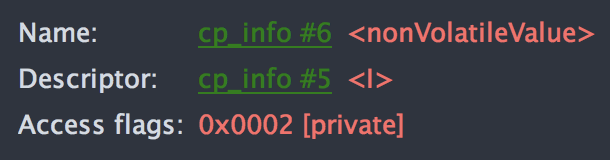
对比如上结果我们可以知道,volatile 和普通变量之间的差别就是字节码上的 access flag 不同,具体来说就是 volatile 变量多了一个 0x0040 的 access flag,这个标记是什么含义呢?我们查看一下 JVM 虚拟机规范的定义就知道了:
ACC_VOLATILE 0x0040 Declared volatile; cannot be cached.
原来 0x0040 是专门用来修饰 volatile 变量的,当虚拟机在处理这种变量的时候需要特殊处理一下,以满足「可见性」和「有序性」约束。
我们翻阅 JVM 虚拟机规范和 JSR 133 可以知道,为了能够在不同的操作系统和硬件平台上都能良好实现 volatile 语义,需要一个平台无关的逻辑抽象来描述这种语义的实现定义,这个可以被称为规范。HotSpot JVM 作为使用最为广泛的 JVM,它的实现很多都是标准的,我们可以看下它内部对于这个规范的描述,在 11 版本的 HotSpot 的 src/hotspot/share/runtime/orderAccess.hpp 中有一个非常好的注释描述:
// This interface is based on the JSR-133 Cookbook for Compiler Writers.
// ... 省略若干注释
// We define four primitive memory barrier operations.
//
// LoadLoad: Load1(s); LoadLoad; Load2
//
// Ensures that Load1 completes (obtains the value it loads from memory)
// before Load2 and any subsequent load operations. Loads before Load1
// may *not* float below Load2 and any subsequent load operations.
//
// StoreStore: Store1(s); StoreStore; Store2
//
// Ensures that Store1 completes (the effect on memory of Store1 is made
// visible to other processors) before Store2 and any subsequent store
// operations. Stores before Store1 may *not* float below Store2 and any
// subsequent store operations.
//
// LoadStore: Load1(s); LoadStore; Store2
//
// Ensures that Load1 completes before Store2 and any subsequent store
// operations. Loads before Load1 may *not* float below Store2 and any
// subsequent store operations.
//
// StoreLoad: Store1(s); StoreLoad; Load2
//
// Ensures that Store1 completes before Load2 and any subsequent load
// operations. Stores before Store1 may *not* float below Load2 and any
// subsequent load operations.
大致意思是说,JSR 133 中定义了四种基本的内存屏障操作:
LoadLoad
作用于:Load1;LoadLoad:Load2,确保 Load1 一定是在 Load2 以及其后的指令之前完成,在指令执行的时候,Load1 绝对不会到 Load2 之后执行;
StoreStore
作用于:Store1;StoreStore:Store2,确保 Store1 一定是在 Store2 以及其后的指令之前完成(同时,Store1 的写入数据会立即被其他 CPU 看到,也就是可见性),在指令执行的时候,Store1 绝对不会到 Store2 之后执行;
LoadStore
作用于:Load1;LoadStore:Store2,确保 Load1 一定是在 Store2 以及其后的指令之前完成,并且 Load1 绝对不会到 Store2 之后执行;
StoreLoad
作用于:Store1;StoreLoad:Load2,确保 Store1 一定在 Load2 以及其后的指令之前完成,并且 Store1 绝对不会到 Load2 之后执行;
从以上的四种内存屏障说明中我们可以看到,volatile 的「有序性」会得到保证,并且 Store 指令也会保证「可见性」。
在 JVM 内部实现 volatile 访问的时候都需要如下格式:
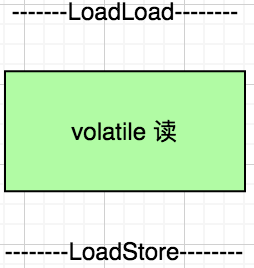
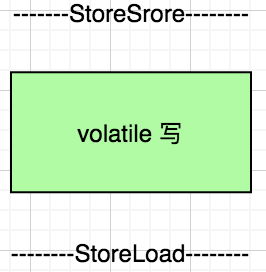
如上两个图描述 volatile 字段在读和写的时候需要的内存屏障操作,我们首先来看读操作,在读操作之前的 LoadLoad 屏障要求这个读操作之前的所有读操作不能在这个读操作之后完成,必须按照上下顺序执行,读操作之后的 LoadStore 要求这个读操作不能在之后的写操作之后完成,必须在之前完成。同样的,写操作前后的屏障也是定义了类似的有序性要求。对于上下文读写操作来说,无非就是如下几种组合:
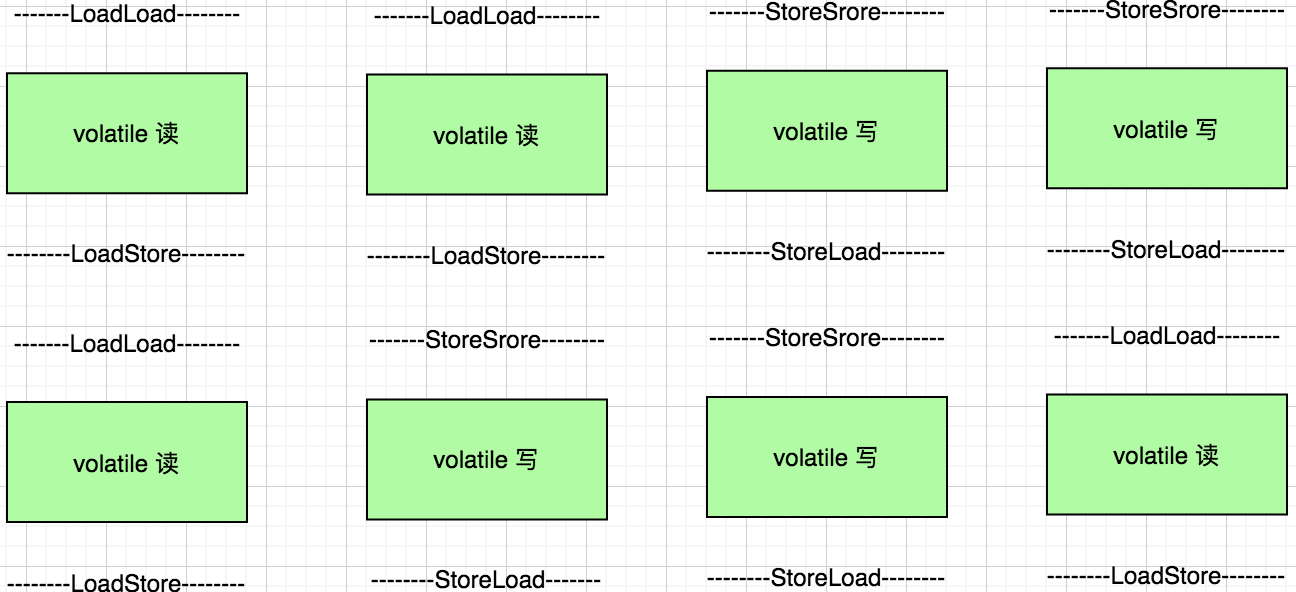
对于 读-读 操作,读操作前面的 LoadLoad 操作要求前后必须有序
对于 读-写 操作,读操作后面的 LoadStore 操作要求前后必须有序
对于 写-写 操作,写操作前面的 StoreStore 操作要求前后必须有序
对于 写-读 操作,写操作后面的 StoreLoad 操作要求前后必须有序
这样我们就知道了,在 JVM 层面通过如上定义的四种内存屏障操作规范了 volatile 的读、写任意组合都是有序的。
这里我们只是讨论完毕了「有序性」是怎么实现的,还没有讨论「可见性」是如何实现的。其实在上面的 HotSpot 注释中我们隐约看到了可见性的描述,貌似这些内存屏障本身不仅仅是保证了「有序性」,还保证了「可见性」。
到底是不是这样了呢?我们先从代码上追踪下怎么实现的吧。
要想基本了解 JVM 是如何实现的字节码执行的,其实我们就看它内部的字节码解释器的执行过程就行了,虽然这个执行器基本完全不用了(基本都会使用模板解释器),但是由于这个解释器本身比较简单,我们可以快速了解执行原理,用来学习正好。
我们翻开 11 HotSpot 的 src/hotspot/share/interpreter/bytecodeinterpreter.cpp 找到执行 getfield 和 getstatic 字节码执行的位置:
...
CASE(_getfield):
CASE(_getstatic):
{
...
if (cache->is_volatile()) {
if (support_IRIW_for_not_multiple_copy_atomic_cpu) {
OrderAccess::fence();
}
...
}
...
}
可以 看到,在访问对象字段的时候,会先判断它是不是 volatile 的,如果是的话,并且当前 CPU 平台支持多核核 atomic 操作的话(现代的绝大多数的 CPU 都支持),那就是调用 OrderAccess::fence(),这个函数的实现是具体平台相关的,所以我们就简单看下 linux 平台的 x86 架构的实现:src/hotspt/os_cpu/linux_x86/orderAccess_linux_x86.hpp:
inline void OrderAccess::fence() {
// always use locked addl since mfence is sometimes expensive
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
compiler_barrier();
}
可以看到无论是 AMD 64 还是 x86 都是使用 lock addl 指令实现的,只是具体的寄存器不同,这里我们先不要深入指令细节,先大概知道是这个指令实现的即可。
出于兴趣,并且笔者本人是做 Android 开发的,想看一下 linux arm 的实现:src/hotspt/os_cpu/linux_arm/orderAccess_linux_arm.hpp:
inline void OrderAccess::fence() { dmb_sy(); }
在看下 dmb_sy 的实现:
inline static void dmb_sy() {
if (!os::is_MP()) {
return;
}
#ifdef AARCH64
__asm__ __volatile__ ("dmb sy" : : : "memory");
#else
if (VM_Version::arm_arch() >= 7) {
#ifdef __thumb__
__asm__ volatile (
"dmb sy": : : "memory");
#else
__asm__ volatile (
".word 0xF57FF050 | 0xf" : : : "memory");
#endif
} else {
intptr_t zero = 0;
__asm__ volatile (
"mcr p15, 0, %0, c7, c10, 5"
: : "r" (zero) : "memory");
}
#endif
}
可以看到大致是使用 dmb sy 指令实现的,还是先不要深入指令细节。
下面我们通过实际的实验来分析一下,到底是不是如上代码中的指令实现的。
硬件平台的实现
HotSpot X86 实现
由于我手上没有 arm 架构的 linux 系统,所以只能先分析在 x86 linux 上分析了,各位抱歉。
首先问一个问题,我们怎么获得 JVM 执行的汇编指令代码?我们知道 JVM 会定期生成「热」代码,以加速代码执行,这就是 JIT,如果我们将 volatile 的操作跑足够多的次数使得 JVM 生成 JIT 热点代码,然后想办法拿到 JIT 的这个热代码不就行了吗?是的,就是这个思路,并且 openjdk 官方提供了一个专门的工具来获取 JIT 热点代码的,它就是 HSDIS(HotSpot Disassmbler),关于 hsdis 怎么安装使用,这里不在啰嗦,请参考笔者之前的文章:Java 并发基石篇 中的做法。
我们的实验代码:
package com.createchance.volatilelearn;
/**
* 研究观察 volatile 的读写底层行为
*
* @author createchance
* @since 2020/5/24
*/
public class ReadWriteVolatile {
private volatile int value = 0;
public void readMethod() {
int dump = value;
}
public void writeMethod() {
value = 10;
}
public static void main(String[] args) {
ReadWriteVolatile readWriteVolatile = new ReadWriteVolatile();
for (int i = 0; i < 1000000000; i++) {
readWriteVolatile.readMethod();
readWriteVolatile.writeMethod();
}
}
}
通过 hsdis 来查看 writeMethod 的热点代码的汇编:
0x000000010f2a462e: mov $0xa,%edi
0x000000010f2a4633: mov %edi,0xc(%rsi)
0x000000010f2a4636: lock addl $0x0,0xffffffffffffffc0(%rsp)
;*putfield value {reexecute=0 rethrow=0 return_oop=0}
; - com.createchance.volatilelearn.ReadWriteVolatile::writeMethod@3 (line 17)
可以看到,这里确使用了 lock addl 指令,这个指令的含义是什么呢?大家可以去查看一下 Intel 开发者手册,可以知道,这个指令主要是给 rsp 寄存器中的值加 0。什么?给一个值加 0?有啥意义啊?看起来没啥意义?其实这是一个讨巧的做法。我们的 volatile 的数据就是存储在 rsp 中的,这个时候给这个值加 0 可以确保这个值不会发生变化,所以核心就是在 lock 的含义上了,lock 有如下作用:
- 在 lock 锁定的时候,如果操作某个数据,那么其他 CPU 核是不能同时操作的,即锁定了
- lock 锁定的指令,不能上下文随意排序执行,必须按照程序上下顺序执行
- 在 lock 锁定操作完毕之后,如果某个数据被修改了,那么需要立即告诉其他 CPU 这个值被修改了,是它们的缓存数据立即失效,需要重新到内存获取
细细品来,这不就是 volatile 的基本语义么?嗯,是的,这就实现了 volatile 的硬件级别的语义。
有人可能要问了,为啥要 lock addl 给加 0 操作呢?直接 lock nop 不是更好吗?至少开销更小啊?嗯,听起来很有道理,但是这么做有如下问题:
- x86 指令集不允许 lock nop,是的,这是「刚」性规定
- 如果使用 nop 就起不到指示其他 CPU 这个数据被修改这个效果了
到这里,我们基本确定了在 linux x86 上就是通过 lock addl 指令来实现 volatile 的硬件级别的语义的。
ART arm 实现
笔者本人是做 Android 开发的,所以自然会想到在 android 平台的 ART 虚拟机是如何实现的。
想要验证 ART 平台的实现难度并不大,我们知道,ART 并不是直接运行 dex 的,而是运行 dex 优化之后的 oat 的,这个 oat 中就有优化之后的二进制指令代码,我们只要拿到这个数据就行了。
我们首先通过 r8 编译器将上面测试代码编译的 class 文件生成 dex:
java -jar ~/Library/Android/sdk/build-tools/28.0.3/lib/d8.jar --release --output ./ com/createchance/volatilelearn/ReadWriteVolatile.class
这样在当前目录下就生成了 classes.dex 文件,然后我们将这个 dex push 到手机上,然后执行 oat 优化:
adb push classes.dex /sdcard/Download/test
adb shell && cd /sdcard/Download/test
dex2oat --dex-file=./classes.dex --oat-file=./classes.oat
这样我们就能在当前目录下得到 classes.oat 文件了,然后我们通过 oatdump 来查看:
oatdump --oat-file=./classes.oat
可以看到测试代码中的写和读方法生成的指令代码:
2: void com.createchance.volatilelearn.ReadWriteVolatile.readMethod() (dex_method_idx=2)
DEX CODE:
0x0000: 5210 0000 | iget v0, v1, I com.createchance.volatilelearn.ReadWriteVolatile.value // field@0
0x0002: 0e00 | return-void
OatMethodOffsets (offset=0x0000070c)
code_offset: 0x000010e1
OatQuickMethodHeader (offset=0x000010c8)
vmap_table: (offset=0x000009cc)
Optimized CodeInfo (number_of_dex_registers=2, number_of_stack_maps=0)
StackMapEncoding (native_pc_bit_offset=0, dex_pc_bit_offset=0, dex_register_map_bit_offset=1, inline_info_bit_offset=1, register_mask_bit_offset=1, stack_mask_index_bit_offset=1, total_bit_size=1)
DexRegisterLocationCatalog (number_of_entries=0, size_in_bytes=0)
QuickMethodFrameInfo
frame_size_in_bytes: 0
core_spill_mask: 0x00004020 (r5, r14)
fp_spill_mask: 0x00000000
vr_stack_locations:
locals: v0[sp + #4294967280]
ins: v1[sp + #4]
method*: v2[sp + #0]
CODE: (code_offset=0x000010e1 size_offset=0x000010dc size=8)...
0x000010e0: 6888 ldr r0, [r1, #8]
0x000010e2: f3bf8f5b dmb ish
0x000010e6: 4770 bx lr
3: void com.createchance.volatilelearn.ReadWriteVolatile.writeMethod() (dex_method_idx=3)
DEX CODE:
0x0000: 1300 0a00 | const/16 v0, #+10
0x0002: 5910 0000 | iput v0, v1, I com.createchance.volatilelearn.ReadWriteVolatile.value // field@0
0x0004: 0e00 | return-void
OatMethodOffsets (offset=0x00000710)
code_offset: 0x00001101
OatQuickMethodHeader (offset=0x000010e8)
vmap_table: (offset=0x000009ec)
Optimized CodeInfo (number_of_dex_registers=2, number_of_stack_maps=0)
StackMapEncoding (native_pc_bit_offset=0, dex_pc_bit_offset=0, dex_register_map_bit_offset=1, inline_info_bit_offset=1, register_mask_bit_offset=1, stack_mask_index_bit_offset=1, total_bit_size=1)
DexRegisterLocationCatalog (number_of_entries=0, size_in_bytes=0)
QuickMethodFrameInfo
frame_size_in_bytes: 0
core_spill_mask: 0x00004020 (r5, r14)
fp_spill_mask: 0x00000000
vr_stack_locations:
locals: v0[sp + #4294967280]
ins: v1[sp + #4]
method*: v2[sp + #0]
CODE: (code_offset=0x00001101 size_offset=0x000010fc size=14)...
0x00001100: 200a movs r0, #10
0x00001102: f3bf8f5b dmb ish
0x00001106: 6088 str r0, [r1, #8]
0x00001108: f3bf8f5b dmb ish
0x0000110c: 4770 bx lr
从上面的输出 CODE 段可以看到二进制指令汇编代码,可以看到,这里确实是通过 dmb 指令实现的,只不过和前面看到 HotSpot 的具体指令不太一样。dmb 究竟是什么指令呢?我们看下 ARM 官方的 datasheet:
Data Memory Barrier acts as a memory barrier. It ensures that all explicit memory accesses that appear in program order before the DMB instruction are observed before any explicit memory accesses that appear in program order after the DMB instruction. It does not affect the ordering of any other instructions executing on the processor.
从上面描述我们了解到:
- dmb 是一个数据内存屏障
- 它确保程序指令执行顺序不会乱掉,指示影响当前指令,不会影响到其他指令
- 并且这个指令之后的指令是 ish,表示内部共享区域,也就是说之后的指令会操作共享区域的数据,因此修改完毕之后,需要及时通知其他 CPU
是的,这就是 arm 平台上的 volatile 语义实现。
总结
到这里,我们就基本梳理了 java volatile 的三个层次的实现:
- Java 语言层面,提供基本语义的定义和抽象
- 字节码上使用 ACC_VOLATILE 来修饰字段,然后 JVM 会通过统一抽象的内存屏障来保证「有序性」和「可见性」
- CPU 硬件实现上,x86 通过 lock addl,arm 通过 DMB 指令来实现
Java volatile 的性能表现怎么样?
有经验的 Java 开发者都知道,Java volatile 会影响到字段的读写性能,那么究竟是怎么样的影响呢?我们来做一个有趣的小实验。
实验代码:
/**
* 研究观察 volatile 的读写性能
*
* @author createchance
* @since 2020/5/24
*/
public class ReadWriteVolatilePref {
private volatile int volatileValue = 0;
private int plainValue = 0;
public void test() {
long start = System.nanoTime();
for (int i = 0; i < 1000000000; i++) {
volatileValue = i;
}
long end = System.nanoTime();
System.out.println("Volatile write duration: " + (end - start) / 100_0000);
start = System.nanoTime();
for (int i = 0; i < 1000000000; i++) {
int dump = volatileValue;
}
end = System.nanoTime();
System.out.println("Volatile read duration: " + (end - start) / 100_0000);
start = System.nanoTime();
for (int i = 0; i < 1000000000; i++) {
plainValue = i;
}
end = System.nanoTime();
System.out.println("Plain write duration: " + (end - start) / 100_0000);
start = System.nanoTime();
for (int i = 0; i < 1000000000; i++) {
int dump = plainValue;
}
end = System.nanoTime();
System.out.println("Plain read duration: " + (end - start) / 100_0000);
}
}
运行结果如下(你可以多运行几次,结果不会有太大出入):
Volatile write duration: 1078
Volatile read duration: 26
Plain write duration: 34
Plain read duration: 2
可以看到最耗时的是 volatile 的写入操作,因为这个写入是会使得各个层级的 cache 都失效,然后写入内存的,因此当然慢啦!
然后可以看到,和普通变量的写入性能相比,发现差别是竟然高达 25 倍之大!
读取性能的差别也是相当大~
这里还没有模拟多线程读写,如果是多线程读写的话,性能差别会更大的!
因此,大家在平常开发中,如果能不用 volatile 就不要用,这个关键字不是「银弹」。
那么 volatile 的性能就只能这样了吗?可以更快吗?这是一个好问题,下面我们探索一下如何优化~
Java Volatile 的性能可以优化吗?
在深入讨论 volatile 性能优化之前,我们需要先了解一下和它相关的基础,有了这个基础之后我们才可以进一步分析。
CPU 封装架构
首先我们需要来了解一下 CPU 多核以及缓存的架构,通常而言,现代 CPU 多核架构如下:
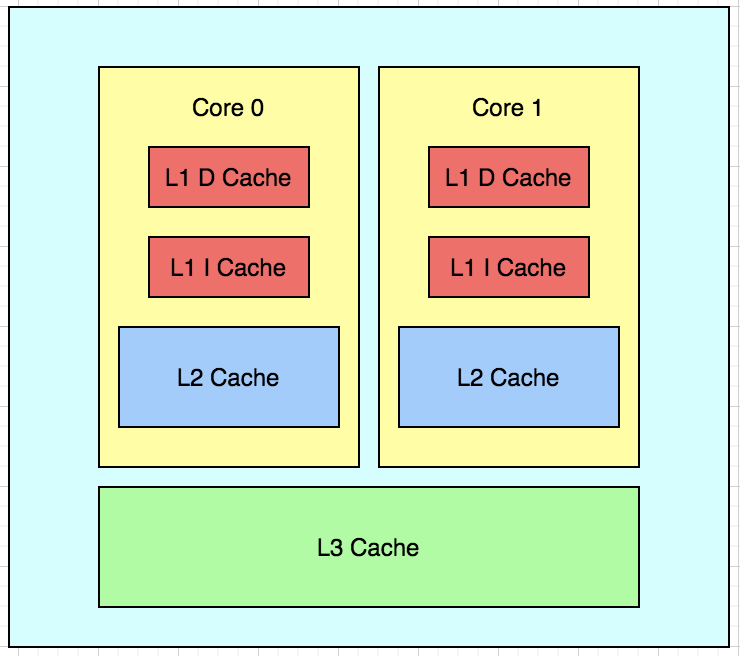
随着 CPU 运行速度的不断提升,CPU 和内存之间的工作频率差距已经非常之大,以至于二者不能直接在一起工作,我们必须借助更加高速的中间缓存设计来间接沟通。这个中间设备称为缓存,因为对于 CPU 而言,内存太慢,如果每次都到内存访问数据肯定是不行的,因此可以这样,每次访问数据的时候,我们不要只取我们需要的那个数据,我们把那个数据周围前后的某一「块」数据都读取出来,这样下次就可以快速的访问这个数据附近的数据了,这个被称为「程序局部性原理」。
经过若干年的发展,为了在速度和成本之间进行平衡,缓存也出现了分层架构,是的,就是缓存的缓存。按照和 CPU 的距离划分,离 CPU 越近的缓存工作速度越快,成本也就越高昂;反之,离 CPU 距离越远,缓存的工作速度越慢,并且成本也越低。因此,就形成了上图的分层缓存架构:
- L1 Cache:也就是第一级缓存,这个离 CPU 非常近,速度最快,并且价格极其昂贵,分为两种:D Cache 数据缓存和 I Cache 指令缓存
- L2 Cache:第二级缓存,提供较高速度访问,价格较为低廉,大小比 L1 大
- L3 Cache:第三级缓存,提供低速度的访问,价格低廉,大小比 L2 大
注意,L1 和 L2 是封装在 CPU 内部某个核中的,也就是这个核独享的,L3 是封装在 CPU 内部的,在多个核之间共享的,有的时候,L3 Cache 不在 CPU 内部,而是在主板上的。
以上几种缓存和内存的工作周期和访问延迟见下表(数据来自网络,可能不准确,大家看个大概即可):
| 从 CPU 到 | 大约需要的 CPU 周期(cycle) | 大约需要的时间(ns) |
|---|---|---|
| 寄存器 | 1 | na |
| L1 Cache | 3 ~ 4 | 0.5 ~ 1 |
| L2 Cache | 10 ~ 20 | 3 ~ 7 |
| L3 Cache | 40 ~ 50 | 15 |
| 内存 | 120 ~ 240 | 60 ~ 120 |
在 Linux 系统中可以如下指令查看 CPU cache 信息:
# 查看一级数据缓存信息
➜ ~ cat /sys/devices/system/cpu/cpu0/cache/index0/type
Data
➜ ~ cat /sys/devices/system/cpu/cpu0/cache/index0/size
32K
➜ ~ cat /sys/devices/system/cpu/cpu0/cache/index0/shared_cpu_list
0,8
# 查看一级指令缓存信息
➜ ~ cat /sys/devices/system/cpu/cpu0/cache/index1/type
Instruction
➜ ~ cat /sys/devices/system/cpu/cpu0/cache/index1/size
32K
➜ ~ cat /sys/devices/system/cpu/cpu0/cache/index1/shared_cpu_list
0,8
# 查看二级缓存信息
➜ ~ cat /sys/devices/system/cpu/cpu0/cache/index2/size
512K
➜ ~ cat /sys/devices/system/cpu/cpu0/cache/index2/shared_cpu_list
0,8
# 查看三级缓存信息
➜ ~ cat /sys/devices/system/cpu/cpu0/cache/index3/size
16384K
➜ ~ cat /sys/devices/system/cpu/cpu0/cache/index3/shared_cpu_list
0-3,8-11
其中 type 表示这个缓存的类型,只有第一级缓存有意义,其他的都是 Unified 的。size 表示这个缓存的大小,shared_cpu_list 表示这个缓存在哪些 CPU 之间共享。从上面的输出可以看出 L1、L2 缓存是在一个核内部独享的,L3 是在多核之间共享的,需要注意的是上面 L1、L2 的 shared_cpu_list 输出为 0,8,并不是两个核,而是一个核两个线程(超线程)。
缓存行和伪共享
上面我们说到了 CPU Cache 的架构,实际上 Cache 并不是数据的来源,实际的数据是来自内存。前面我们提到了程序的「局部性」原理,也就是 CPU 在访问内存的时候并不是一次读取一个,而是一次性读区一块数据,提升性能。
这里读取的块被称作为 cache line,不同机器的 cache line 大小是不一样的,大小都是 2 的幂次方,通常最常见到的大小都是 64 Byte,在 Linux 系统上可以如下获取缓存行大小:
➜ ~ cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
64
➜ ~ cat /sys/devices/system/cpu/cpu0/cache/index1/coherency_line_size
64
➜ ~ cat /sys/devices/system/cpu/cpu0/cache/index2/coherency_line_size
64
➜ ~ cat /sys/devices/system/cpu/cpu0/cache/index3/coherency_line_size
64
可以看到,从 L1 ~ L3 的 cache line 都是 64 Bytes,到这里你先记住这个东西,后面我们会依据这个搞点好玩的。
下面这个图展示了缓存行的概念:
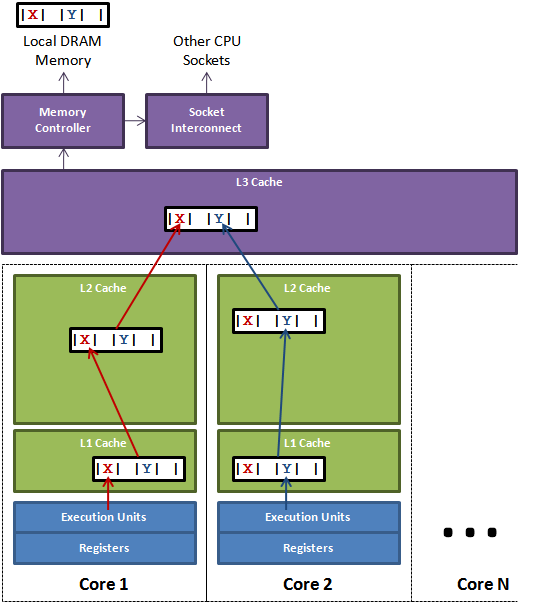
图中,core 1 将缓存行中的 X 修改了,core 2 将 Y 修改了,最终的修改都会映射到 L3 Cache 中,并最终写会内存。
缓存行充分利用了程序的「局部性原理」,可以极大提升整体性能。但是这里有一个问题,就是如果一个 CPU 修改了它自己内部缓存中的缓存行,那么这个修改怎么让其他的 CPU 知道呢?其实需要一种机制和方案来确保这件事情,那么这个机制就称为缓存一致性协议。上面我们看到某个变量在内存中,看起来各个 CPU 之间是共享这个内存空间的,但是实际上每个 CPU 直接通过访问各自内部的 cache 来访问的,并不是直接访问的,这是看起来像是共享的,实际上并不是共享的,这就是伪共享(false sharing)。
缓存一致性协议
我们看到了,既然 CPU 是直接从缓存中读取数据的,并且各个核之间有自己独享的 cache,这就必然存在一个问题,就是一致性问题。当一个核修改了自己 cache 中的数据,这个修改怎么通知到其他核中的 cache,这需要一个协议来保证能及时感知。
能够做到这种保证的协议称为「缓存一致性」协议,这种协议有很多,各个 CPU 厂商有各自的实现:MSI、MESI、MOSI、Synapse、Firefly 等等。这里,我们以 Intel 的 MESI 来分析一下,其他的协议大同小异。
MESI 是如下四种操作的缩写:
- 已修改Modified (M)
缓存行是脏的(*dirty*),与主存的值不同。如果别的CPU内核要读主存这块数据,该缓存行必须回写到主存,状态变为共享(S)。
- 独占Exclusive (E)
缓存行只在当前缓存中,但是干净的(clean),缓存数据同于主存数据。当别的缓存读取它时,状态变为共享;当前写数据时,变为已修改状态。
- 共享Shared (S)
缓存行也存在于其它缓存中且是干净的。缓存行可以在任意时刻抛弃。
- 无效Invalid (I)
缓存行是无效的,再次访问的时候,必须立即从下一级中获取
这四种状态对于任意一个缓存行的相容关系如下(来自维基百科)):
| M | E | S | I | |
|---|---|---|---|---|
| M |  |
|
|
 |
| E | |
|
|
|
| S | |
|
|
|
| I | |
|
|
|
当块标记为 M (已修改), 在其他缓存中的数据副本被标记为I(无效)。
上表中的 表示不可相容的操作, 表示可以相容的操作。
几个优化方案
上面我们看到了 CPU 中的缓存行,这个缓存行在大部分的机器上都是 64 个字节,那么如果我们有两个变量,然后这两个变量在同一个缓存行上的话,如果有两个线程独立修改这两个变量的话,可能会知道两个 CPU 核中的 cache line 反复失效,不时地去内存上读取,这样可能性能会急剧下降,下面我们要做一个实验。
实验代码:
/**
* 研究 CPU 缓存行对整体性能的影响
*
* @author createchance
* @since 2020/5/24
*/
public class CacheLinePadding01 {
private final long CYCLE_TIMES = 10_0000_0000L;
private long[] array = new long[2];
public void test() throws InterruptedException {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for (long i = 0; i < CYCLE_TIMES; i++) {
array[0] = i;
}
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
for (long i = 0; i < CYCLE_TIMES; i++) {
array[1] = i;
}
}
});
long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
long end = System.nanoTime();
System.out.println("Duration: " + (end - start) / 100_0000);
}
}
这段代码比较简单,一个 2 个大小的 long 数组,然后有两个线程同时并发修改第 0 个和第 1 个。
运行 5 次,查看输出:
Duration: 382
Duration: 338
Duration: 323
Duration: 313
Duration: 337
如果我们将测试代码修改为:
测试代码 2:
/**
* 研究 CPU 缓存行对整体性能的影响
*
* @author createchance
* @since 2020/5/24
*/
public class CacheLinePadding02 {
private final long CYCLE_TIMES = 10_0000_0000L;
private long[] array = new long[16];
public void test() throws InterruptedException {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for (long i = 0; i < CYCLE_TIMES; i++) {
array[0] = i;
}
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
for (long i = 0; i < CYCLE_TIMES; i++) {
array[8] = i;
}
}
});
long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
long end = System.nanoTime();
System.out.println("Duration: " + (end - start) / 100_0000);
}
}
这次我们将数组长度调整为 16 个,第一个线程赋值第 0 个,第二个线程赋值第 8 个,一个 long 是 8 个字节,也就是第一个线程访问的数据和第二个线程访问的数据肯定不在一个缓存行中,这样避免缓存行伪共享带来的性能问题。
这样会不会更快呢?让我们运行 5 次,查看输出:
Duration: 311
Duration: 318
Duration: 324
Duration: 322
Duration: 314
整体上来看,貌似比上一个快一点,但是差距不明显。
这是因为,CPU 将一个缓存行修改之后,其他 CPU 虽然知道这个被修改了,但是并不一定会立即去内存访问,而是有一定的周期的。因此这里的差距不会太明显。
这时,我们将数组修改为 volatile,让每次缓存行失效都强制 CPU 去内存读,看看这一次差距会不会被拉大。
测试代码 3:
/**
* 研究 CPU 缓存行对整体性能的影响
*
* @author createchance
* @since 2020/5/24
*/
public class CacheLinePadding01 {
private final long CYCLE_TIMES = 10_0000_0000L;
private volatile long[] array = new long[2];
public void test() throws InterruptedException {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for (long i = 0; i < CYCLE_TIMES; i++) {
array[0] = i;
}
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
for (long i = 0; i < CYCLE_TIMES; i++) {
array[1] = i;
}
}
});
long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
long end = System.nanoTime();
System.out.println("Duration: " + (end - start) / 100_0000);
}
}
运行 5 次,查看结果:
Duration: 7565
Duration: 7264
Duration: 6658
Duration: 9277
Duration: 6809
然后我们将上面测试代码 2 中的数组修改为 volatile:
测试代码 4
/**
* 研究 CPU 缓存行对整体性能的影响
*
* @author createchance
* @since 2020/5/24
*/
public class CacheLinePadding02 {
private final long CYCLE_TIMES = 10_0000_0000L;
private volatile long[] array = new long[16];
public void test() throws InterruptedException {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for (long i = 0; i < CYCLE_TIMES; i++) {
array[0] = i;
}
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
for (long i = 0; i < CYCLE_TIMES; i++) {
array[8] = i;
}
}
});
long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
long end = System.nanoTime();
System.out.println("Duration: " + (end - start) / 100_0000);
}
}
运行 5 次,查看结果:
Duration: 2753
Duration: 2974
Duration: 2904
Duration: 2931
Duration: 2756
果然,不出我们所料~整体性能提升 1 倍有余!
上面我们使用一个长长的数组来填充缓存行,有的时候我们不能使用数组,那我们是不是可以使用 long 数据来手动填充呢?我们试一试吧!
测试代码 5
/**
* 研究手动填充 cache line 对性能的影响
*
* @author createchance
* @since 2020/5/24
*/
public class CacheLinePadding03 {
private final long CYCLE_TIMES = 10_0000_0000L;
private static class Inner {
volatile long value = 0L;
}
private Inner[] array = new Inner[2];
public CacheLinePadding03() {
array[0] = new Inner();
array[1] = new Inner();
}
public void test() throws InterruptedException {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for (long i = 0; i < CYCLE_TIMES; i++) {
array[0].value = i;
}
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
for (long i = 0; i < CYCLE_TIMES; i++) {
array[1].value = i;
}
}
});
long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
long end = System.nanoTime();
System.out.println("Duration: " + (end - start) / 100_0000);
}
}
这时一个没有手动填充的例子,array 数组中的数据大概率在一个缓存行中的,现在我们看下运行 3 次的输出:
Duration: 43962
Duration: 47395
Duration: 44312
然后我们修改程序如下:
测试程序 6
/**
* 研究手动填充 cache line 对性能的影响
*
* @author createchance
* @since 2020/5/24
*/
public class CacheLinePadding03 {
private final long CYCLE_TIMES = 10_0000_0000L;
private static class Inner {
private long p1, p2, p3, p4, p5, p6, p7;
volatile long value = 0L;
}
private Inner[] array = new Inner[2];
public CacheLinePadding03() {
array[0] = new Inner();
array[1] = new Inner();
}
public void test() throws InterruptedException {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for (long i = 0; i < CYCLE_TIMES; i++) {
array[0].value = i;
}
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
for (long i = 0; i < CYCLE_TIMES; i++) {
array[1].value = i;
}
}
});
long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
long end = System.nanoTime();
System.out.println("Duration: " + (end - start) / 100_0000);
}
}
这一次,我们只是在 Inner 的 value 前加了一系列的占位字段,目的是填充 cache line,只要把 64 Byte 占满就行。
运行 5 次,查看输出:
Duration: 8017
Duration: 6680
Duration: 6638
Duration: 6639
Duration: 6906
天呐!一个小小的填充居然将整体的性能提升了 5 倍以上!
是的,这就是填充缓存行的威力!
但是,追求完美的我们会进一步问,这里我们填充了 7 个 long 数据,有点多啊,能不能少一点呢?这样内存占用会小一点啊?嗯,有道理,其实我们仔细想一想,我们这里的数组大小是 2,也就是说,数组中对象只要大小大于 64 / 2 = 32 不就行了吗?这样两个数据就不能在一个 cache line 中共存了。说干就干,我们修改一下:
测试程序 7
/**
* 研究手动填充 cache line 对性能的影响
*
* @author createchance
* @since 2020/5/24
*/
public class CacheLinePadding03 {
private final long CYCLE_TIMES = 10_0000_0000L;
private static class Inner {
private long p1, p2, p3;
private byte p4;
volatile long value = 0L;
}
private Inner[] array = new Inner[2];
public CacheLinePadding03() {
array[0] = new Inner();
array[1] = new Inner();
}
public void test() throws InterruptedException {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for (long i = 0; i < CYCLE_TIMES; i++) {
array[0].value = i;
}
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
for (long i = 0; i < CYCLE_TIMES; i++) {
array[1].value = i;
}
}
});
long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
long end = System.nanoTime();
System.out.println("Duration: " + (end - start) / 100_0000);
}
}
这一次,我们选择填充 25 个字节,让整体大小为 25 + 8 = 33 个字节,这是理论上的最小值了。
运行 5 次,查看结果:
Duration: 7006
Duration: 6731
Duration: 6526
Duration: 6664
Duration: 6966
嗯,果然和刚才差不多!真赞!
但是,这个时候我们的吹毛求疵的毛病又犯了,如果每次都手写这个 padding 的代码,岂不是很无聊?这明明就是模板代码,完美的工程师不能容忍代码中有大量这种无聊代码出现的!嗯,有道理!并且 OpenJDK 官方也意识到了这个问题,在 1.8 的时候开发出了 Contended 注解,关于这个注解开发细节可以查看 OpenJDK 内部开发沟通邮件:https://mail.openjdk.java.net/pipermail/hotspot-dev/2012-November/007309.html
这个注解可以在 JDK 代码中多处看到,尤其是 JUC 中,大家可以自己去查看。
这个注解的定义如下:
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.FIELD, ElementType.TYPE})
public @interface Contended {
String value() default "";
}
这个注解是运行时的,并且只能作用于类型和字段。
需要注意的是,这个注解只供 JDK 内部使用,外部是不能「直接」使用的,就像 unsafe 那样!
但是我们仍然有办法使用,看下代码:
测试代码 8
/**
* 学习 Contended 注解使用
*
* @author createchance
* @since 2020/5/28
*/
public class CacheLinePadding04 {
private final long CYCLE_TIMES = 10_0000_0000L;
private static class Inner {
@sun.misc.Contended
volatile long contendedField = 0L;
}
private Inner[] array = new Inner[2];
public CacheLinePadding04() {
array[0] = new Inner();
array[1] = new Inner();
}
public void test() throws InterruptedException {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for (long i = 0; i < CYCLE_TIMES; i++) {
array[0].contendedField = i;
}
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
for (long i = 0; i < CYCLE_TIMES; i++) {
array[1].contendedField = i;
}
}
});
long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
long end = System.nanoTime();
System.out.println("Duration: " + (end - start) / 100_0000);
}
public static void main(String[] args) throws InterruptedException {
CacheLinePadding04 cacheLinePadding04 = new CacheLinePadding04();
cacheLinePadding04.test();
}
}
还是同样的方法,只是这一次我们不再手动 padding 了,而是通过 Contended 注解进行。
但是这个代码在 IDE 中是报错的,因为 IDE 编译环境是标准的,当让不允许你直接使用啦!但是我们通过万能的命令进行编译(请通过 JDK8 进行编译,不要使用高版本):
➜ volatilelearn git:(master) ✗ javac CacheLinePadding04.java -d ~/Downloads/tmp
CacheLinePadding04.java:11: 警告: Contended是内部专用 API, 可能会在未来发行版中删除
@sun.misc.Contended
^
1 个警告
嗯,编译成功了,但是给了一个警告,告诉我们这个内部专用,我们无福消受~不过没关系,这个时候发挥程序员默认忽略 Warning 的优良传统,直接无视它~
那么我们需要怎样运行它呢?因为这个注解是一个运行时注解,在启动 JVM 的时候给一个指定的参数,告诉 JVM 碰到这个注解的 field 帮我特殊处理一下,通过如下命令运行:
java -XX:-RestrictContended com.createchance.volatilelearn.CacheLinePadding04
指定 -RestrictContended 告诉 JVM 不要限制 Contended 注解即可,下面运行 5 次看看:
Duration: 6492
Duration: 6531
Duration: 6537
Duration: 6545
Duration: 6505
嗯,和我们手动 padding 效果一样!这就对了!
等等,这个注解是怎么实现的呢?其实很简单上面的 JDK 内部邮件中作者就已经解释了:
Note that we use 128 bytes, twice the cache line size on most hardware
to adjust for adjacent sector prefetchers extending the false sharing
collisions to two cache lines.
很简单,就是运行时在字段后面自动添加 128 Bytes 的填充,和我们手动填充效果一样!这里还说明了,使用 128 而不是 64 是因为要覆盖绝大多数的设备,有些后端设备的 cache line 就是 128 Bytes 的!
总结
到这里我们就梳理完毕 volatile 的优化方案了,其实很简单,就是充分利用缓存行填充的原理,尽量使两个 volatile 变量不要在一个缓存行中!
有的同学可能会说,你的这个优化方案太 trick 了,现实中真的有人会这么干吗?是的,真的有人这么干!一个典型的例子就是 Disruptor 队列,这个移动端开发的同学可能不太了解,不过后端的同学应该很了解,他是号称史上「最快」单机并发队列,没有之一。我们看看它的核心数据结构 RingBuffer 中的一些写法:
public static final long INITIAL_CURSOR_VALUE = Sequence.INITIAL_VALUE;
protected long p1, p2, p3, p4, p5, p6, p7;
想必到这里,就不用我多解释了吧~当然,人家号称史上最快肯定不是就这一招,人家内部的大招多着呢,大家感兴趣可以深入了解下~
推荐一篇美团的分析文章:https://tech.meituan.com/2016/11/18/disruptor.html